Source
Summary of the jep480 document.
Purpose of This Post
- Introduce a concurrency programming style that can eliminate common risks from cancellation and shutdown.
- Improve the observability of concurrent code.
Motivation
- Developers manage complexity by dividing tasks into subtasks.
- In single-threaded code, subtasks are executed sequentially, but if subtasks are independent, running them concurrently can improve performance.
- However, managing many threads is very difficult.
Unstructured concurrency with ExecutorService
Example code using ExecutorService introduced in Java 5 for concurrency, showing what problems arise without structured concurrency.
Example Code
| |
handle()
- Represents a server application task
- Receives a request and runs two subtasks:
- subtask1 - calls findUser()
- subtask2 - calls fetchOrder()
executor service (esvc)
- ExecutorService returns a Future for each subtask
- Schedules each subtask to run concurrently
Future.get()
- handle() blocks, waiting for the subtask results
Independence
- Each subtask can succeed or fail independently
- Failure = throws an exception
Problem Scenarios
When failures occur, understanding the lifetime of threads can be very complex.
Scenario 1 - Thread leak due to exception
Flow
findUser()failsuser.get()causeshandle()to fail- But
fetchOrder()does not fail and its thread keeps running (=thread leak)
Problem
- The still-running
fetchOrder()- Wastes resources
- In the worst case, can block other tasks
- Unnecessarily holds external connections, causing delays for new requests
Scenario 2 - Thread leak due to failed interrupt propagation
Flow
handle()is interrupted- The interrupt is not propagated to subtasks
findUser()andfetchOrder()keep running in their threads
Problem
- Even though handle()’s thread is interrupted, both subtasks keep running, leaking threads
Scenario 3 - Unnecessary waiting
Flow
findUser()takes a long time- While waiting for
findUser(),fetchOrder()fails handle()does not canceluser.get()and blocks unnecessarily- Only after
user.get()returns doeshandle()fail
Problem
- If
user.get()fails,handle()does not fail immediately, unnecessarily occupying a thread
What is the problem? (Problem Definition)
Problem 1 - Logical task-subtask relationships are only in code
- The logical structure is not represented at runtime, only in the developer’s mind
- Code and runtime handling are not the same, increasing the chance of human error
- Makes error diagnosis and problem solving very difficult
- Monitoring tools like thread dumps show
handle(),findUser(), andfetchOrder()as unrelated call stacks
- Monitoring tools like thread dumps show
Problem 2 - Too much freedom with ExecutorService
- ExecutorService and Future allow unstructured concurrency patterns
Task structure should reflect code structure
Single-threaded code is predictable, easy to read, and easy to monitor. Let’s rewrite the above concurrent code as single-threaded code.
Code
| |
- The body block of handle() is the task
- Methods called within the body block are subtasks
- Called methods must return a value or fail
Code Explanation
fetchOrder()cannot run untilfindUser()completes (success or failure)- If
findUser()fails,fetchOrder()is not run - If
findUser()fails,handle()also fails - When running
findUser(), the call stack shows both findUser() and handle(), making it clear thatfindUser()is running because ofhandle()
Features of structured code
- Subtasks must return a value or throw an error to the calling task, so the task can control its subtasks
- If a subtask fails, the parent task can cancel other subtasks or fail itself
- Subtasks cannot outlive the task, so subtasks are children of the task (like parent-child processes)
- Subtasks within the same task are related
- If the task fails, subtasks are not run
- If a subtask fails, other subtasks are not run
- The task-subtask hierarchy is realized in the runtime call stack
All these constraints are enforced by the block structure of the code.
Desired properties in concurrent programming
- Like single-threaded code, the parent-child relationship between tasks and subtasks should be realized not only in code structure but also at runtime.
Structured concurrency
Definition
Structured concurrency is an approach that keeps the natural relationship between tasks and subtasks, making concurrent code easier to read and manage.
Principle
If a task splits into concurrent subtasks, then they all return to the same place, namely the task’s code block.
Idea
- Code blocks provide clear entry and exit points for execution flow
- The lifetime of work is strictly nested to match the syntactic nesting of code blocks
Benefits
- Entry and exit points are clear, so the lifetime of subtasks is limited to the parent task’s block
- Since each subtask’s lifetime is limited to the parent task, you can manage and control subtasks as a single logical unit
- Subtasks’ lifetimes are tied to the parent task, so you can represent the hierarchy as a tree
Kotlin
How is the concept of structured concurrency applied in Kotlin?
YouTube: KotlinConf 2019 - Roman Elizarov - Structured Concurrency

Only in CoroutineScope can you run subtasks concurrently
| |
- You can only launch coroutines (coroutine builders) inside a coroutineScope
- The lifetime of coroutines created inside coroutineScope is limited to the parent task’s coroutineScope lifetime
The task waits until all subtasks are finished
| |
- Coroutines created with
launchrun concurrently doWorldonly completes after all launched coroutines complete, so “Done” is printed after 2 seconds
Cancelling the task cancels all subtasks
| |
If a subtask fails in a coroutine scope, other subtasks are cancelled
Failure != cancellation
- Failure: an exception is thrown
- Cancellation: coroutine is cancelled (job.cancel())
| |
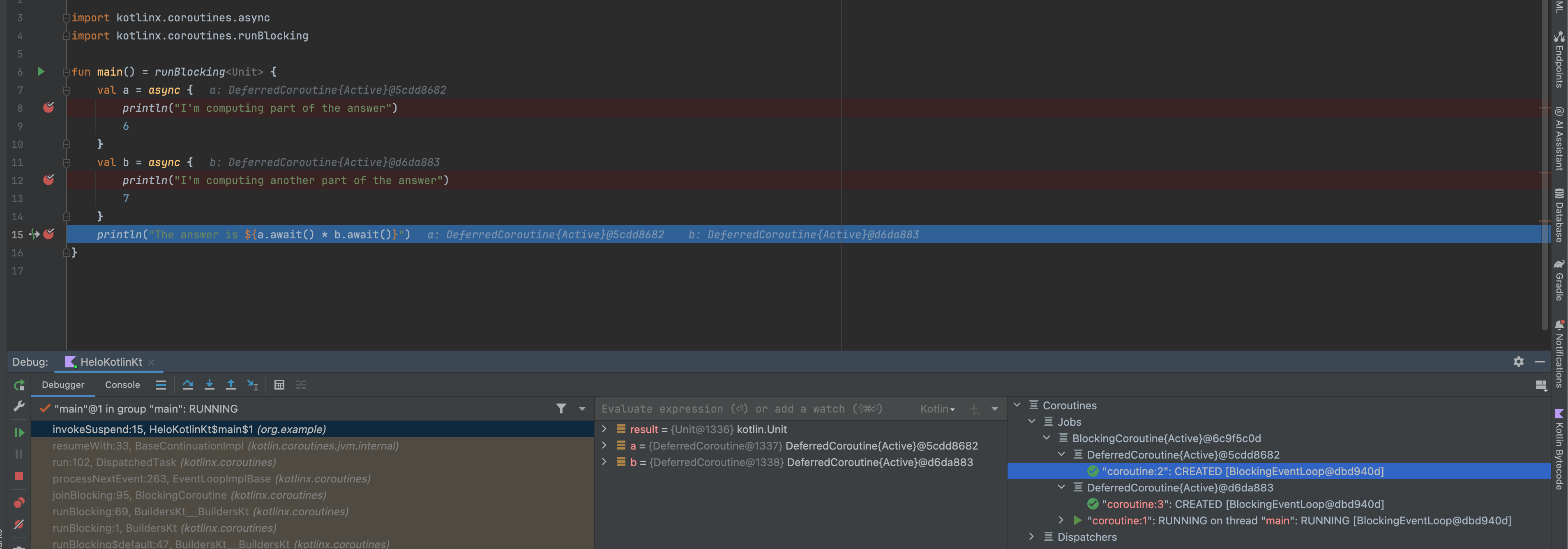
Debugging - Monitoring tools show task-subtask as a tree
BlockingCoroutine
- DeferredCoroutine
- coroutine2
- DeferredCoroutine
- coroutine3
- coroutine1